Выбираем GPU для ИИ: Видеокарты NVIDIA RTX 4090 и 5090 vs L40S 48GB

Автор: АлександрОпубликовано: 16 октября, 2025

Выбор между потребительской RTX 4090 и серверной L40S для ИИ — это выбор между мощностью и масштабируемостью. Обе на чипе AD102, но с разной специализацией. Лакмусовая бумажка — объем памяти. 48 ГБ против 24 ГБ решает, сможете ли вы запустить сложнейшую модель или будете искать обходные пути.
Теоретически есть новый игрок — RTX 5090 на 32 ГБ GDDR7. Но на практике она в большом дефиците, а также ощущается нехватка объема памяти для проффесиональной работы с ИИ, что возвращает нас к исходному выбору: универсальность 4090 или профессиональный задел L40S c 48Gb.
Наше сравнение видеокарт поможет вам принять оптимальное решение с учетом специфики ваших задач и бюджетных ограничений.
Сравниваем «начинку»: ядра, память и мощность
Внутренние компоненты заметно отличаются. GPU NVIDIA L40S получил больше вычислительных ресурсов: 18 176 ядер CUDA против 16 384 у GPU RTX 4090. Однако для задач искусственного интеллекта особенно важны тензорные ядра — специальные блоки для матричных вычислений. GPU-адаптер NVIDIA L40S оснащен 568 такими ядрами, тогда как у RTX 4090 их 456. Эта разница в 11% напрямую влияет на скорость работы с PyTorch CUDA и другими фреймворками для глубокого обучения.
У видеокарты для работы с нейросейтами NVIDIA L40S используется память типа GDDR6, инженерный выбор в пользу памяти GDDR6 для ускорителя L40S — это не компромисс, а стратегическое решение. Ключевыми аргументами стали сниженное тепловыделение и энергопотребление. Это критически важно для многопроцессорных серверных стоек, где плотность размещения и стабильность работы превосходят по важности пиковую скорость. При работе с fp16 и fp8 и компактными моделями система упирается не в объем, а в скорость доступа к данным. И здесь оптимизированная память L40S демонстрирует паритет, а иногда и превосходство над более «прожорливыми» аналогами, обеспечивая стабильный и быстрый поток вычислений.
Показатель L40S в 0,305 TFLOPS/Вт против 0,184 TFLOPS/Вт у RTX 4090 говорит сам за себя: профессиональный ускоритель почти на 70% эффективнее преобразует энергию в вычисления. Это не просто цифры из тестов, а прямая экономия для дата-центров и облачных платформ, где счет за электричество — одна из ключевых статей расходов. L40S не просто мощнее и имеет больше памяти — он умнее в потреблении ресурсов.
На практике производительность GPU — величина нелинейная. Для моделей, умещающихся в 24 ГБ, мы наблюдаем «плато эффективности»: последние драйверы NVIDIA так грамотно управляют ресурсами, что разница между картами может быть минимальной, измеряемой в процентах. Однако этот паритет рушится, как только мы переходим красную черту объема VRAM. Большие языковые модели и генерация высокодетализированных изображений — это уже другая весовая категория. Здесь вычислительные ядра простаивают в ожидании данных, и единственный ключ к раскрытию их потенциала — объем памяти. L40S с его 48 ГБ не просто быстрее — он выполняет задачи, которые для RTX 4090 попросту недоступны.
Несмотря на появление GeForce RTX 5090 на 32 ГБ, обе карты всё равно остаются актуальными для большинства AI-задач 2025 года, хотя и работают с разной эффективностью. А объем памяти в 32GB часто остается недостаточным для работы с нейросетями.
Тестируем скорость обучения нейросетей: сравниваем возможности
Согласно исследованию AIME, проведенному в 2025 году, профессиональный ускоритель L40S демонстрирует стабильное преимущество в 10–15% над игровым флагманом RTX 4090 в задаче обучения модели BERT Large в PyTorch. Этот разрыв — прямое следствие аппаратного превосходства L40S: его 18 176 CUDA-ядер и 568 тензорных ядер против 16 384 и 456 у RTX 4090 обеспечивают более высокую вычислительную плотность для профессиональных рабочих нагрузок.

Критически важным фактором, без которого любое обсуждение производительности GPU неполно, является режим компиляции в PyTorch. Этот механизм выполняет статическую компиляцию графа вычислений, кардинально меняя принцип его исполнения. При подключении этого режима скорость операций возрастает в 1,5–4 раза. Наибольший эффект наблюдается на высокопроизводительных ускорителях, где компилятор устраняет интерпретационные накладные расходы PyTorch. Система начинает работать на пределе своих аппаратных возможностей, а не возможностей интерпретатора.
Автоматическая смешанная точность (AMP) еще больше раскрывает потенциал NVIDIA. Переход с fp32 на fp16 способен более чем удвоить скорость обучения, обеспечивая мгновенный прирост производительности для практически любой модели. Современные карты также поддерживают формат fp8, который еще больше повышает эффективность при сохранении приемлемой точности.
В многопроцессорных конфигурациях GPU NVIDIA 4090 демонстрирует ограниченное масштабирование. Согласно тестам AIME видеокарта L40S с 48GB показывает значительно лучшие результаты, что делает эту видеокарту идеальной для облачных серверов с GPU и систем с несколькими процессорами.
При обучении крупных моделей GPU NVIDIA L40S с 48 ГБ памяти не требует трюков вроде gradient checkpointing, в отличие от RTX 4090 с ее 24 ГБ. Это дает прямое преимущество при работе с такими гигантами, как Qwen3, или при создании сложных генеративных моделей, например Stable Diffusion.
Критерий выбора прост:
- L40S 48Gb решает задачи, которые другим не по силам из-за нехватки памяти.
- RTX 4090 дает максимальную скорость за свои деньги в сегменте до 13B параметров.
Скорость работы с готовыми моделями: тесты инференса
Когда речь заходит о масштабных языковых моделях от 70B параметров и выше, GPU-адаптер NVIDIA L40S 48 ГБ становится не просто предпочтительным, а единственно возможным решением из этой пары. Объема памяти RTX 4090 даже с учетом 4-битной квантизации попросту не хватает. Особенно это актуально при работе с новыми версиями нейросети Qwen3, которые требуют значительных объемов видеопамяти.
Генеративные AI-модели также демонстрируют интересный паттерн производительности. При использовании нейросети Stable Diffusion для создания изображений стандартного разрешения разница между картами минимальна. Однако при рендеринге изображений сверхвысокого разрешения (1024 × 1024+) ключевым преимуществом L40S становится объем видеопамяти. Именно 48 ГБ позволяют карте хранить все промежуточные данные вычислений, избегая узких мест, характерных для решений с меньшим буфером. L40S на 20% быстрее A100 в задачах генеративного AI, но уступает примерно настолько же зарекомендовавшему себя, но дорогому H100.
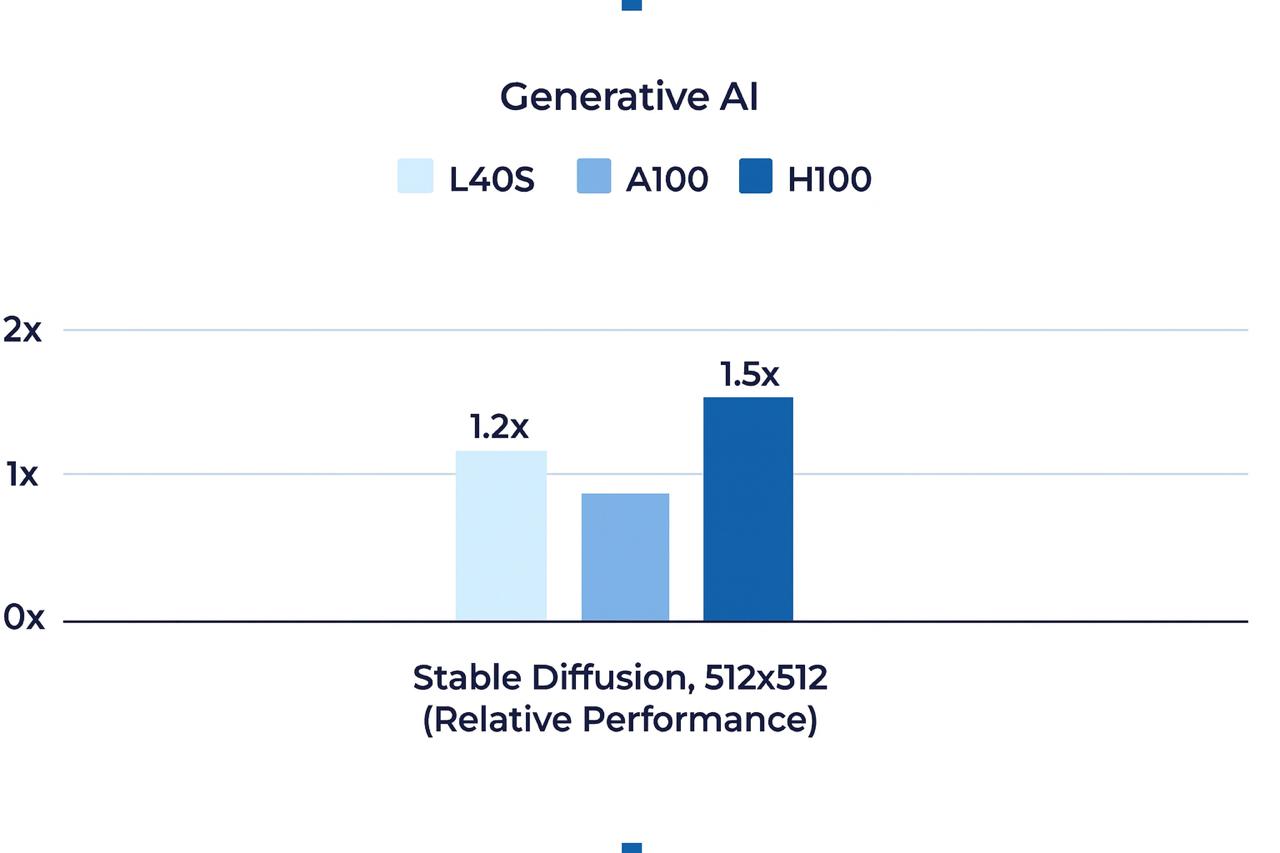
В области компьютерного зрения NVIDIA L40S не менее хороша. По данным тестов NVIDIA, эта карта обрабатывает более 23 000 изображений в секунду при использовании ResNet-50v1.5 с размером батча 8, а при увеличении батча до 32 этот показатель возрастает до 29 000 изображений. Такая производительность критична для систем реального времени и облачных GPU-серверов, обслуживающих множество одновременных запросов.
Выбор карты для задач инференса зависит от двух вещей: размера модели и того, где она будет работать:
- Выбирайте RTX 4090, если вы работаете с небольшими моделями и вам нужна максимальная скорость отклика и аренда ее в облаке или покупка будет значительно дешевле чем L40S
- Выбирайте L40S 48GB, если ваша модель не помещается в 24 ГБ или вы запускаете ее на сервере для множества пользователей. Ее главный козырь — большой объем памяти для сложных задач и масштабирования. У нас в облаке mClouds, аренда GPU для работы с ИИ NVIDIA L40S стоит сопоставимо аренде 4090 с 24GB памяти.
Непрерывная работа: что важно для круглосуточной эффективности
В центрах обработки данных и на серверах, работающих круглосуточно без перерывов, разница между игровой и профессиональной видеокартой становится критически важной. Здесь имеет значение не только производительность, но и надежность, энергопотребление и возможности администрирования.
L40S тратит всего 300 Вт — на 150 Вт меньше, чем RTX 4090 (450 Вт). Это прямая экономия на электричестве плюс проще и дешевле охлаждение. Для сервера, работающего круглый год, такая разница очень ощутима. Важным плюсом для профессиональной работы - L40S работает стабильнее в непрерывной работе 24/7.
Еще L40S умеет делить свои ресурсы между задачами в Kubernetes (это называется time-slicing). Представьте: на одной карте можно одновременно запустить и генерацию изображений в Stable Diffusion, и несколько чат-ботов на Qwen, и интерфейс OpenWebUI, просто выделив каждому сервису нужную долю мощности.
Важное преимущество L40S — полная поддержка vGPU. Эта технология превращает один физический ускоритель в несколько виртуальных, позволяя гибко распределять его ресурсы между десятками пользователей или контейнеров. Можно работать с VDI в облаке и разделить мощность L40S и ее объем памяти между несколькими серверами.
Например, ваша команда может запустить отдельные виртуалки для разных проектов: один разработчик тестирует модели Ollama, другой работает с инференс LLM, третий обрабатывает данные через PyTorch CUDA. У каждого свои драйверы на видеокарту NVIDIA, свои настройки и изолированное окружение. В результате вы получаете эффективную работу в режиме 24/7 и максимальную окупаемость оборудования. GPU 4090, как и 5090 таких возможностей не предоставляет, что сильно ограничивает ее гибкость в корпоративных средах.
Система охлаждения играет важную роль в длительной работе. L40S использует пассивный радиатор без вентиляторов, что повышает надежность: нет движущихся частей, которые могут сломаться. RTX 4090 с тремя вентиляторами имеет больше точек потенциального отказа, особенно при круглосуточной работе под нагрузкой.
В критически важных системах, например для обработки финансовых или медицинских данных, L40S предлагает поддержку ECC-памяти (Error Correction Code). Эта технология автоматически исправляет случайные ошибки в памяти, гарантируя точность вычислений в форматах fp16 и fp8.
Если вам нужен сервер для непрерывной работы с большими моделями Llama или для постоянно доступных сервисов генерации изображений — профессиональная L40S обеспечит гораздо более высокую надежность.
Финансовый вопрос: сколько стоит доступ к AI-ускорителям
Если смотреть на покупку, то здесь всё просто: RTX 4090 за 200–250 тысяч рублей — это вариант для тех, кто только начинает или не хочет вкладываться сильно, плюс, конечно нужно иметь мощную начинку для ее работы. А вот L40S — совсем другая история: карта обойдется в 0,8–1,1 млн рублей, и это еще без учета специального сервера под нее.
Но есть и хорошие новости. Раньше аренда профессиональных карт, таких как L40S и A100, в облаке была значительно дороже игровых. Сейчас же разница почти исчезла — можно спокойно брать L40S для экспериментов по цене, близкой к аренде RTX 4090. Отличный способ попробовать мощное железо без гигантских вложений.
Месячная аренда облачного сервера с GPU на базе RTX 4090 часто обходится до 50–60 тысяч рублей и это уже с мощностями CPU , RAM и NVMe диском, готовая инфраструктура для старта работы. Раньше за сопоставимую конфигурацию с L40S пришлось бы отдать около 90–100 тысяч рублей в месяц. Теперь профессиональная карта стала доступнее. У нас в mClouds, например, аренда GPU-сервера с ней обходится не дороже, а иногда даже дешевле, чем с RTX 4090.
При принятии решения об аренде сервера с GPU стоит учитывать не только стоимость самой видеокарты, но и другие параметры: объем оперативной памяти, скорость процессора, наличие быстрых NVMe-накопителей, ширину канала связи. Все эти факторы влияют на общую производительность вашего AI-проекта, будь то OpenWebUI для работы с LLM или тяжелые задачи обработки видео через нейронные сети.
Для каких задач подходит каждая видеокарта
В мире искусственного интеллекта нет универсального GPU-решения для всех задач. Оптимальный выбор зависит от ваших конкретных потребностей, масштаба проекта и бюджетных ограничений.
Когда выбирать RTX 4090
Индивидуальным разработчикам, исследователям и небольшим командам стоит обратить внимание на GPU RTX 4090. Эта видеокарта предлагает отличный баланс производительности и стоимости для задач, не требующих более 24 ГБ памяти:
- Эксперименты с нейросетями среднего размера — идеально для моделей до 13B параметров с квантизацией, таких как Llama 3 8B или ранние версии Qwen нейросети.
- Локальная разработка и тестирование — запуск Ollama моделей на домашней рабочей станции с современными драйверами на видеокарту NVIDIA.
- Генерация изображений — работа со Stable Diffusion нейросетью при стандартных разрешениях (до 1024 × 1024).
- Быстрые итерации — тестирование гипотез и прототипирование без необходимости в дорогостоящей серверной инфраструктуре.
- Обработка видео — ускорение обработки видеоматериалов с использованием PyTorch CUDA.
RTX 4090 особенно выгодна для периодических задач, где не требуется круглосуточная работа и достаточно 24GB оперативной памяти или 32GB оперативной памяти GPU, если речь про RTX 5090
Когда выбирать L40S 48GB
Профессионалам и организациям, работающим с масштабными проектами и требующим максимальной надежности, стоит обратить внимание на NVIDIA L40S 48 ГБ:
- Крупные языковые модели — работа с моделями свыше 13B параметров, такими как Qwen3 и полноразмерные версии Llama.
- Серверные решения 24/7 — постоянно доступные сервисы на GPU-серверах с высокой отказоустойчивостью.
- Многопользовательские системы — виртуализация GPU-адаптера для обслуживания нескольких команд или приложений одновременно.
- Контейнеризированные приложения — развертывание в Kubernetes с поддержкой time-slicing.
- Высокоточные вычисления — задачи, требующие ECC-памяти для обеспечения целостности данных при выполнении fp8 и fp16 операций.
- Интерфейсы для пользователей — хостинг OpenWebUI с параллельной обработкой запросов от многих клиентов.
L40S оправдывает себя в корпоративных средах, где требуется максимальная гибкость управления ресурсами и возможности масштабирования.
Экономичные альтернативы
Если бюджет ограничен, а высокопроизводительные вычисления требуются лишь периодически, рассмотрите аренду GPU вместо покупки:
- Вы сможете использовать мощные карты, только когда они действительно нужны.
- Облачный сервер с GPU предоставляет доступ к новейшему оборудованию без капитальных затрат.
- Аренда сервера с GPU на ограниченный промежуток времени идеально подходит для обучения моделей, которое требуется провести лишь несколько раз.
С развитием технологий квантизации многие модели стали более эффективными и могут работать даже на менее мощных GPU. Например, некоторые версии Qwen после оптимизации способны функционировать на картах с 8–16 ГБ памяти.
Подбирайте решение под задачи вашего проекта и не переплачивайте за избыточные возможности, которые вам не понадобятся. В то же время помните о потенциале роста: иногда лучше взять видеокарту с запасом, чтобы избежать ограничений в будущем.
16 октября, 2025
 Предновогодний дайджест 2025 года: что улучшили за год
Предновогодний дайджест 2025 года: что улучшили за годПрокачали мощность и скорость облачной платформы с GPU, вошли в топ-10 российских GPU-провайдеров, участвовали в ключевых событиях индустрии, а также писали много интересного в блогах на сайте и Хабре!
25 декабря, 2025 Выбираем видеокарту для ИИ до 24GB: обзор и сравнение NVIDIA L4 и T4
Выбираем видеокарту для ИИ до 24GB: обзор и сравнение NVIDIA L4 и T4Сравниваем видеокарты для работы с нейросетями NVIDIA T4 16GB и её обновление в виде NVIDIA L4 24Gb. Детально про технические характеристики, проверим реальную производительность в задачах машинного обучения и разберемся, какая из них лучше справляется с инференсом больших языковых моделей и другими ML-задачами. Это поможет понять, стоит ли в 2026 году выбирать устаревшую T4 или лучше присмотреться к L4.
03 декабря, 2025 Ноябрьский дайджест: тестируем S3 и развиваем GPU-платформу
Ноябрьский дайджест: тестируем S3 и развиваем GPU-платформуВ ноябре тестируем наше S3 хранилище, открыли предзаказ на новейшие GPU NVIDIA RTX Pro 6000 Blackwell Server Edition 96GB и cнизили стоимость аренды сервера с видеокартой NVIDIA L4 24GB. А также написали новые статьи и сделали ряд апдейтов облачной платформы в ноябре.
02 декабря, 2025