Оптимизация Postgres и MS SQL для работы с 1С

Автор: АлександрОпубликовано: 10 января, 2025

1С – это система, предназначенная для автоматизации бизнес-процессов внутри компании, в частности, бухгалтерского и управленческого учета, а также экономической и и организационной деятельности. Понимая всю значимость этого сервиса под него выделяются огромные вычислительные и дисковые ресурсы, за его работоспособностью пристально следят. Поэтому оптимизация данного сервиса – это процесс довольно необходимый, так как от этого может зависеть скорость выполнения бизнес-задач.
Общая рекомендация
Общей рекомендацией является разнесение СУБД и базы данных по разным дискам. Это один из самых распространенных и действенных способов сделать работу СУБД быстрее. Теперь рассмотрим оптимизацию двух поддерживаемых 1C СУБД – MSSQL и PostgreSQL
Postgres
СУБД PostgreSQL может быть использована в случае, когда сервер 1С разворачивается на Linux. Рассмотрим основные настройки, которые могут значительно повысить производительность сервера. Все изменения будут производиться в конфигурационном файле postgresql, расположенном по пути /etc/postgresql/<версия>/main/postgresql.conf
Выделим основные параметры, влияющие на производительность сервера:
max_connections – количество одновременно подключающихся пользователей. Рассчитывается, как правило, экспериментальным путем
shared_buffers - объем памяти, выделенной PostgreSQL для совместного кеша страниц. Эта память разделяется между всеми процессами PostgreSQL. Рекомендуется устанавливать в четверть от всего объема RAM (RAM/4)
work_mem - Лимит памяти для обработки одного запроса. Значение индивидуально для каждой сессии. Рекомендуется устанавливать, рассчитывая по формуле RAM/32..64 или из диапазона 32MB..128MB
maintenance_work_mem - Лимит памяти для обслуживающих задач, например по сбору статистики (ANALYZE), сборке мусора (VACUUM), создания индексов (CREATE INDEX) и добавления внешних ключей. Рекомендуется указывать либо по формуле RAM/16..32 или work_mem * 4 или из диапазона 256MB..4GB. Размер должен быть равен размеру самого большого индекса на диске.
max_files_per_process - количество файлов, обрабатываемое одним процессорным ядром.
max_worker_processes - максимальное количество процессов. Указывается равным количеству ядер процессора
max_parallel_workers - максимальное количество одновременно работающих процессов. Рекомендуем указывать равным параметру max_worker_processes.
max_parallel_maintenance_workers – максимальное количество потоков, выполняющих служебные задания. Рекомендуем ставить число, в два раза меньше, чем max_worker_processes
max_parallel_workers_per_gather - Задаёт максимальное число рабочих процессов, которые могут запускаться одним узлом Gather или Gather Merge. Рекомендуется выставлять значение, равное параметру max_parallel_maintenance_workers
effective_cache_size - оценка планировщика запроса о размере дискового кэша, доступного для одного запроса. Это представление влияет на оценку стоимости использования индекса. Высчитывается по формуле RAM - shared_buffers
temp_buffers - Максимальное количество страниц для временных таблиц. То есть, это верхний лимит размера временных таблиц в каждой сессии. Рекомендуем указывать 256MB
huge_pages – Поддержка больших страниц памяти. Рекомендуем устанавливать значение off или try
autovacuum – включение автоматической очистки памяти. Рекомендуем всегда включать (cтавить значение on)
autovacuum_max_workers –определяет количество постоянно работающих фоновиков по очистке устаревших версий данных и обсчету статистики. Рекомендуем устанавливать как половину от количества CPU
autovacuum_vacuum_cost_limit – верхний предел «цены» процесса автоочистки. Рекомендуем ставить значение -1.
autovacuum_naptime - время сна процесса автоочистки. Слишком большая величина будет приводить к тому, что таблицы не будут успевать «чиститься», что приведет у роста размера и снижению производительности работы. Малая величина приведет к бесполезной нагрузке. Рекомендуем выставить в 20 секунд
effective_io_concurrency - оценочное значение одновременных запросов к дисковой системе, которые она может обслужить единовременно. Рекомендуем ставить в интервале от 100 до 200
random_page_cost - стоимость чтения случайной страницы (по умолчанию 4). Чем меньше seek time дисковой системы тем меньше (но > 1.0) должен быть этот параметр. Излишне большое значение параметра увеличивает склонность PostgreSQL к выбору планов со сканированием всей таблицы. Выбор значения зависит от типа диска, на котором располагается база данных: 1.5-2.0 для RAID, 1.1-1.3 для SSD, 0.4 для NVMe
maintenance_io_concurrency - Оценочное значение для обслуживающих процессов, которые выполняются в различных клиентских сеансах.
fsync – включение/выключение сброса буферов на диск. Повышает нагрузку на систему, но снижает риск потери данных в случае внезапного отключения питания у сервера. Рекомендуем включать (значение on)
synchronous_commit – включение/выключение синхронизации с диском в момент коммита. Создает риск потери последних нескольких транзакций (в течении 0.5-1 секунды), но гарантирует целостность базы данных, в цепочке коммитов гарантированно отсутствуют пропуски. В выключенном состоянии значительно увеличивает производительность.
row_security - включение/выключение контроля разрешения уровня записи. Рекомендуем выключать.
bgwriter_delay - время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер. Рекомендуем устанавливать значение в 20 миллисекунд.
bgwriter_lru_multiplier и bgwriter_lru_maxpages - параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл bgwriter записывает не больше, чем было записано в прошлый цикл, умноженное на bgwriter_lru_multiplier, но не больше чемbgwriter_lru_maxpages. Рекомендуемые значения: bgwriter_lru_multiplier - 4, bgwriter_lru_maxpages - 400
commit_delay - пауза (в микросекундах) перед выполнением сохранения WAL. Рекомендуем устанавливать в 1000
commit_siblings - минимальное число одновременно открытых транзакций, при котором будет добавляться задержка commit_delay. Необходим для группового коммита нескольких транзакций. Имеет смысл включать, если темп транзакций превосходит 1000 TPS. Иначе это не возымеет никакого эффекта
min_wal_size и max_wal_size - минимальное и максимальный объем WAL файлов. Устанавливаются по правилу: min_wal_size = 512MB .. 4G и max_wal_size = 2 * min_wal_size.
max_files_per_process - Максимальное количество открытых файлов на один процесс PostreSQL. Рекомендуем устанавливать в 1000
max_locks_per_transaction - Максимальное число блокировок индексов/таблиц в одной транзакции. Рекомендуем указать значение 256
standard_conforming_strings – Разрешение/запрет использовать символ \ для экранирования. Для разрешения рекомендуется установить параметр в off
escape_string_warning - разрешить/запретить выдавать предупреждение об использовании символа \ для экранирования. Для запрета рекомендуется выставить значение off
Так же мы рекомендуем загружать и устанавливать специальную версию PostgreSQL с сайта 1C, нежели, чем использовать версию из пакетной базы linux-дистрибутива или из репозитория Postgres. Данная версия изначально оптимизирована и заточена под работу с 1C, что может сказаться на итоговой производительности сервиса в целом.
MS SQL
MSSQL сервер в качестве СУБД рекомендуется в тех случаях, когда 1C разворачивается на ОС Windows.
Настройка сервера здесь отличается от Postgres: вам не придется редактировать текстовый файл: все изменения можно сделать в графическом интерфейсе Microsoft SSMS, подключившись к серверу MS SQL.
Основным параметром, который следует изменить – это Boost SQL Server Priority, расположенный по пути Server properties -> Advanced -> Miscellaneous
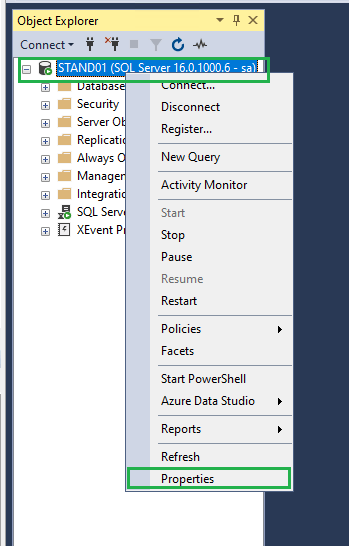
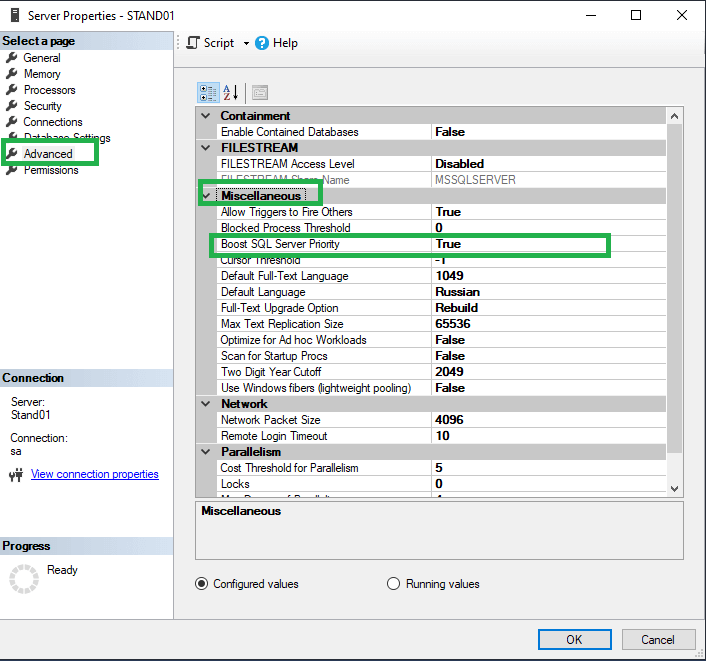
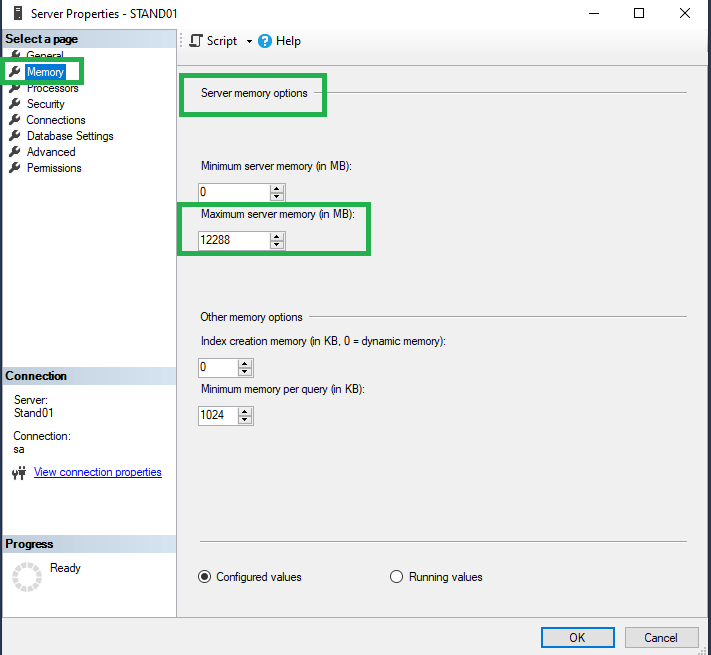
Следующим немаловажным параметром является Maximum Server memory, находящийся по пути Server properties-> Memory -> Server memory options. Мы рекомендуем выставлять три четверти от всего объема оперативной памяти на сервере.
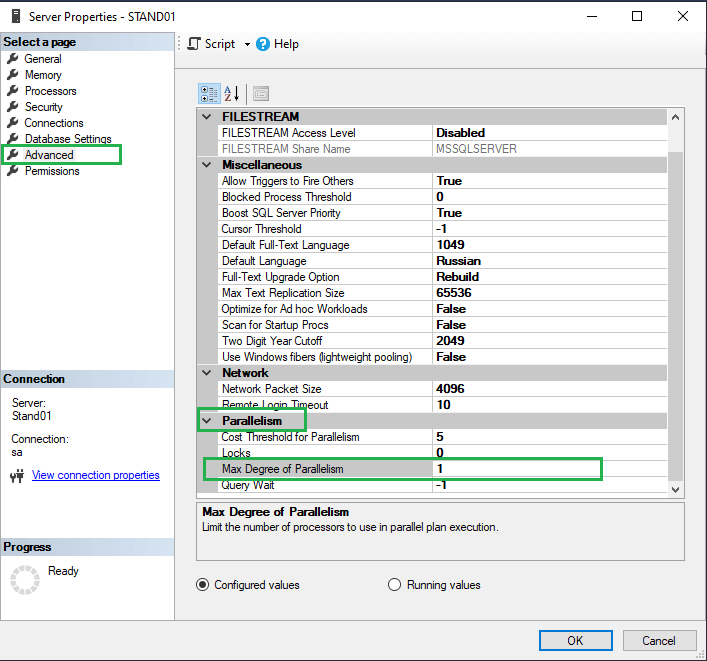
Далее, следующим параметром будет Max Degree of Parallelism – параметр, определяющий, во сколько потоков может выполняться один запрос. По умолчанию параметр равен 0, это означает, что сервер сам подбирает число потоков. Для баз с характерной для 1С нагрузкой рекомендуется поставить данный параметр в значение 1, т.к. в большинстве случаев это положительно скажется на работе запросов. Находится параметр по пути Server properties-> Advanced -> Parallelism
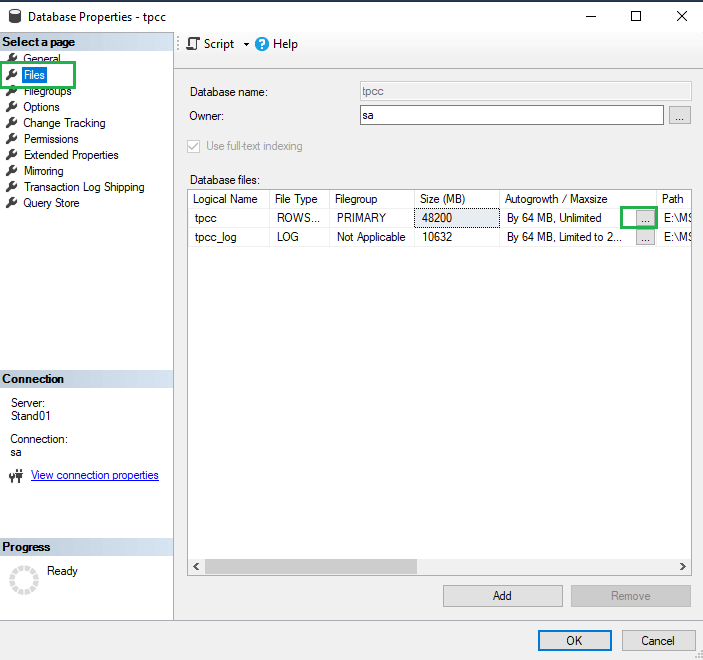
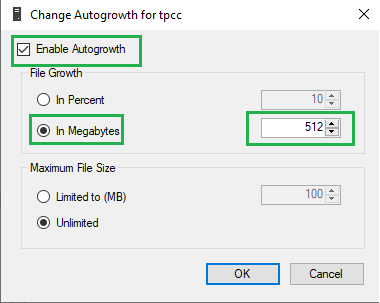
Следующим действием мы рекомендуем изменить размер автоматического увеличения файлов базы данных. Это величина, на которую будет увеличен размер файла базы данных, когда он будет заполнен. Если поставить слишком маленький размер авторасширения, тогда файл будет слишком часто расширяться, на что будет уходить время. Рекомендуем установить значение от 512 МБ до 5 ГБ. Параметр находится по пути SQL Server -> нужная база данных -> Свойства -> Файлы и возле каждого из файлов установить размер увеличения.
Также некоторые источники рекомендуют отключать антивирус для повышения производительности. Мы вам делать этого не рекомендуем, так как безопасность вашего сервера значительно снижается, и он становится подверженным заражению различными вирусами.
Итог
Подводя итог, можно резюмировать, что настройки СУБД для 1С – это не очень сложный процесс, но уникальный для каждого случая. В этой статье были рассмотрены лишь настройки СУБД - максимальная же производительность достигается путем их сочетания с изменениями других параметров, таких как, например, изменение режима электропитания сервера или его регулярного обслуживания. Но даже следуя только нашим рекомендациям, вы сможете оптимизировать работу СУБД для сервера 1С, повысить его производительность и обеспечить наилучшее взаимодействие.
10 января, 2025
 Как создать и настроить кластер серверов для 1С на Linux
Как создать и настроить кластер серверов для 1С на LinuxКак правильно настроить кластер серверов для 1С на Linux? Разбираем ключевые этапы: выбор инфраструктуры, настройку отказоустойчивости, масштабируемость и производительность
27 марта, 2025 Как настроить публикацию базы 1С на веб-сервере с https и защитой
Как настроить публикацию базы 1С на веб-сервере с https и защитойКак настроить веб-доступ к базе 1С через HTTPS: разбираем установку и настройку Apache, подключение SSL-сертификатов и настройку редиректа с HTTP на HTTPS для защиты данных и удобной работы
17 марта, 2025 Развертывание сервера 1С на Linux: полный гайд на примере Astra Linux
Развертывание сервера 1С на Linux: полный гайд на примере Astra LinuxКак установить сервер 1С на Astra Linux: разбираем процесс пошагово, рассматриваем настройку ключей HASP и даем советы по администрированию.
20 февраля, 2025