Как начать работать с ИИ Whisper: тестируем производительность разных платформ

Автор: АлександрОпубликовано: 15 января, 2025

Нейросети всё чаще используют для решения различных задач: от создания текстового и визуального контента до прогнозирования и анализа данных. Однако, чтобы обеспечить их максимальную эффективность, важно понимать, с каким «железом» и операционными системами ИИ работает быстрее.
В этой статье мы протестируем нейросеть, предназначенную для преобразования речи в текст. Мы сравним производительность вычислений для разных CPU, видеокарт и ОС. А еще разберемся, как настроить ПО, и покажем, как его можно использовать.
Что такое Whisper и что мы хотим выяснить
Whisper — это мощная нейронная сеть, предназначенная для обработки и преобразования аудио в текст.
Одно из главных преимуществ нейросети — способность работать на различных конфигурациях оборудования: от центральных процессоров (CPU) до графических процессоров (GPU). Мы решили провести эксперимент, чтобы выяснить, насколько различается производительность на разных устройствах.
Мы стремимся понять:
- Насколько быстро Whisper может обрабатывать аудио на разных устройствах.
- Какие конфигурации подходят для реального использования в бизнесе.
Для оценки производительности нейросети Whisper мы провели тестирование на процессорах Intel и AMD, а также на видеокартах NVIDIA. Кроме того, сравнили работу на двух операционных системах — Windows и Ubuntu.
Тесты выполнялись на виртуальных машинах с такими характеристиками:
- Операционная система: Windows Server 2022.
- Аппаратная конфигурация: 4 vCPU, 32 Гб RAM, 60 Гб хранилища.
- Программное обеспечение: CUDA 12.4, драйвер NVIDIA 538.46.
Для тестирования и оценки используем бенчмарк, который опубликовали на GitHub.
Тестирование процессоров (CPU)
При выполнении вычислений на процессорах Whisper обрабатывает аудио в режиме FP32 (32-битная точность вычислений с плавающей точкой). Этот режим обеспечивает высокую точность, но требует больше времени обработки в сравнении с FP16, который используется на GPU.
Для тестирования мы выбрали следующие процессоры:
- Intel Core i7-11700KF: десктопный процессор 11-го поколения, подходящий для обычных рабочих станций.
- Intel Xeon Gold 6354: серверный процессор с высокой производительностью, специально разработанный для вычислительных нагрузок.
- AMD EPYC 9374F: процессор серверного класса от AMD, известный своей мощностью при работе с параллельными задачами.
Результаты тестирования на ОС Windows:
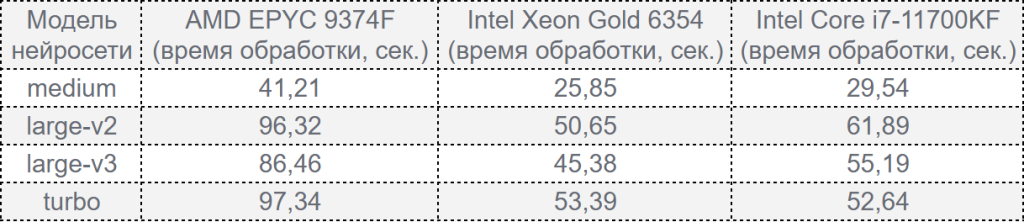
Наши выводы:
- Intel Xeon Gold 6354 показывает наилучшую производительность во всех тестах, превосходя AMD EPYC 9374F и Intel Core i7-11700KF. Однако десктопный процессор Core i7 демонстрирует результаты, близкие к серверному процессору Intel Xeon Gold 6354, что делает его экономически выгодным вариантом для задач вне корпоративного уровня.
- AMD EPYC 9374F, несмотря на высокую мощность для параллельных нагрузок, уступает процессорам Intel в задачах, требующих однопоточной производительности, как в данном тесте.
- Модель turbo нейросети Whisper хотя и требует больше ресурсов, обеспечивает на Intel Core i7-11700KF более высокую скорость обработки по сравнению с более крупными моделями large-v2 и large-v3.
Тестирование графических процессоров
Whisper демонстрирует значительно лучшую производительность на графических процессорах благодаря формату FP16, который обеспечивает высокую скорость обработки. Для теста мы использовали видеокарты NVIDIA L4 и NVIDIA A16 (4Q и 8Q — 4 Гб и 8 Гб видеопамяти у профиля соответственно).
Результаты производительности на L4:
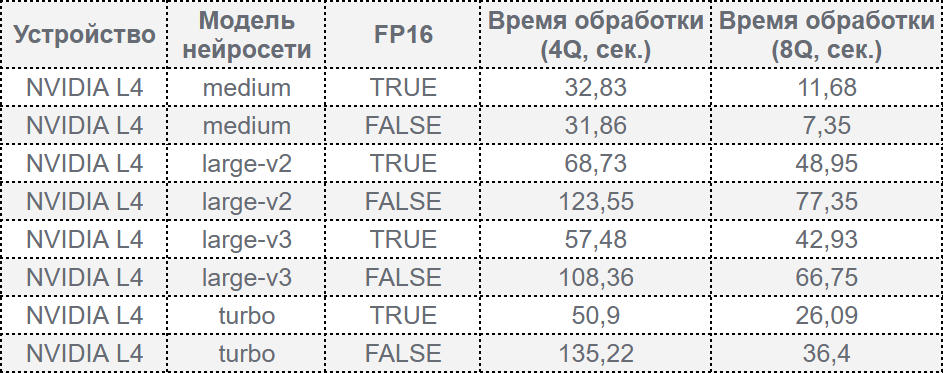
Результаты производительности на A16:
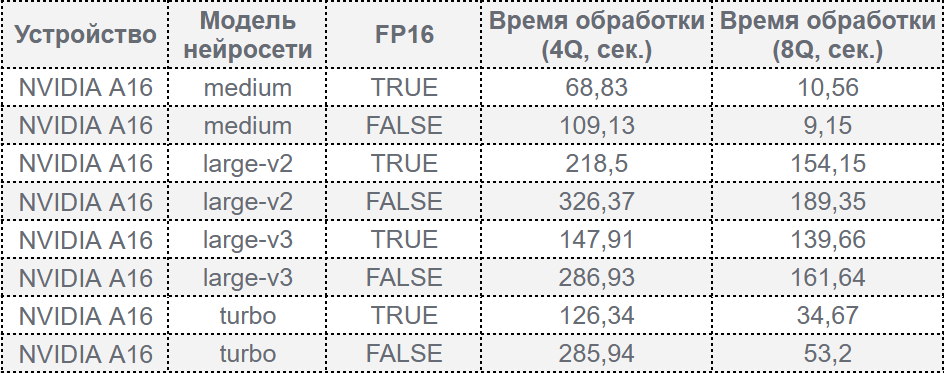
Наши выводы:
- NVIDIA L4 показывает превосходную производительность в режиме 8Q для всех моделей, обгоняя A16 на 68% для моделей large-v2/v3 и на 24% для турборежима.
- Режим FP16 значительно сокращает время обработки по сравнению с FP32, особенно на более сложных моделях (large-v2 и large-v3).
Сравнение операционных систем: Windows и Ubuntu
Для анализа влияния операционной системы на производительность Whisper мы провели тесты на Windows Server 2022 и Ubuntu. В обоих случаях использовалось идентичное оборудование.
Результаты производительности:
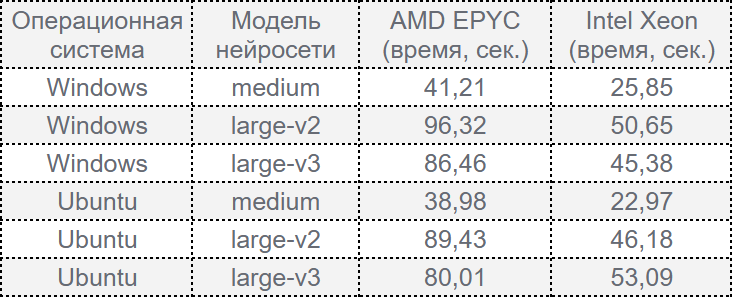
Наши выводы:
- Ubuntu дает небольшое увеличение производительности (в среднем на 5–10%) по сравнению с Windows. Это преимущество объясняется лучшей оптимизацией Ubuntu для серверных задач и обработки данных.
- В случае использования Intel Xeon на Ubuntu время обработки сокращается еще больше, делая эту комбинацию особенно подходящей для серверных приложений.
- Разница между операционными системами не столь критична, чтобы кардинально влиять на выбор платформы.
Как установить и настроить Whisper
В нашем примере мы реализуем следующий сценарий: менеджер провел созвон, и теперь нам нужно преобразовать запись его разговора, выявить суть и поставить оценку работе менеджера для проверки его эффективности.
Для работы нам потребуется выполнить следующие шаги:
- Выполнить установку необходимой нейросети для работы — это Whisper.
- Выполнить преобразование аудиофайла записи разговора менеджера.
- Проанализировать текст разговора и оценить работу менеджера.
Чтобы работать с Whisper, нам необходимо подготовить оборудование и программное обеспечение. Установку будем выполнять на виртуальной машине с недавно вышедшей Windows Server 2025. Выполним следующие шаги.
Установка Python
Python — это основной язык программирования, с которым мы будем работать для настройки и запуска нейросети Whisper. Мы используем современную стабильную версию Python 3.10.11.
- Перейдите на официальный сайт Python.
- Скачайте установочный файл для вашей операционной системы (Windows, macOS или Linux).
- Запустите установку. Обязательно отметьте галочку Add Python to PATH, чтобы не пришлось вручную настраивать путь к Python в системе.
- Нажмите кнопку Install Now и дождитесь завершения установки.
- После завершения проверьте, что Python установлен. Откройте терминал (PowerShell для Windows) и выполните команду:
python --versionПри успешной установке вы увидите версию Python, например Python 3.10.11.
Установка менеджера пакетов Chocolatey (только для Windows)
Chocolatey — это удобный менеджер пакетов для Windows, который позволяет легко устанавливать необходимые программы и библиотеки. Он избавляет от необходимости вручную скачивать и настраивать утилиты, такие как FFmpeg.
- Перейдите на сайт Chocolatey.
- Выберите раздел Individual в инструкции.
- Скопируйте команду из шага 2 инструкции и выполните ее в PowerShell от имени администратора:
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.SecurityProtocolType]::Tls12; Invoke-Expression ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))
4. После завершения установки проверьте, что Chocolatey работает. Выполните команду:
chocoЕсли команда выведет справку, то всё установлено правильно.
Chocolatey упростит установку FFmpeg и других инструментов, которые нам потребуются.
Установка Whisper
Мы будем использовать его библиотеку, разработанную OpenAI, с помощью Python и менеджера пакетов pip (уже установлен вместе с Python).
- Откройте терминал (PowerShell или cmd в Windows).
- Выполните следующую команду:
pip install -U openai-whisper3. Дождитесь завершения установки. После установки Whisper можно будет использовать для работы с аудиофайлами.
Установка FFmpeg
FFmpeg — это мощный инструмент для обработки мультимедийных данных (аудио и видео). Whisper использует его для работы с аудио. Установка осуществляется через Chocolatey:
- Откройте PowerShell от имени администратора.
- Выполните команду:
choco install ffmpeg

3. После завершения установки проверьте, что FFmpeg доступен. Выполните команду:
ffmpeg -version
Если команда выводит информацию о версии FFmpeg, значит, установка прошла успешно.
Установка PyTorch
PyTorch — это библиотека для машинного обучения, которая поддерживает работу с нейросетями на CPU и GPU. Она обязательна для работы модели Whisper.
- Перейдите на сайт PyTorch.
- В конфигураторе выберите параметры вашей системы (например, Windows, Python, версия CUDA). Чтобы по максимуму использовать поддержку CUDA в PyTorch, желательно, чтобы ваша система включала графический процессор NVIDIA (как в нашем тестировании).
 Однако, если в вашей конфигурации нет видеокарты с CUDA, мы можем выполнить установку для CPU.
Однако, если в вашей конфигурации нет видеокарты с CUDA, мы можем выполнить установку для CPU. - Скопируйте команду установки и выполните ее в терминале. Пример команды:
install torch torchvision torchaudio
4. После установки проверьте, что PyTorch работает. Откройте Python в терминале:
pythonВнутри Python выполните:
import torchprint(torch.__version__)
Если выводится версия PyTorch, библиотека установлена и готова к работе.
Установка языка программирования Rust
Некоторые зависимости Whisper требуют наличия компилятора языка Rust. Установите его с помощью pip:
pip install setuptools-rust
Подготовка рабочей среды
- Создайте отдельную папку для вашего проекта. Например
mkdir whisper_projectcd whisper_project
2. Поместите аудиофайл для обработки в эту папку, чтобы позже вы могли указать путь к нему
Теперь среда готова, и вы можете приступить к работе с Whisper.
Как подготовить аудиофайл к обработке
После завершения установки всех инструментов мы готовы использовать Whisper для обработки аудиофайлов и последующей транскрибации.
- Поместите аудиофайл, который вы хотите преобразовать в текст (например, audio.mp3), в созданную папку.
- В терминале PowerShell выполните команду для запуска Whisper:
whisper audio.mp3 --language Russian --model turbo
Вот что значат параметры команды:
- --language Russian: указывает, что язык аудио — русский;
- --model turbo: выбирает модель Whisper с названием turbo, которая обеспечивает быстрое выполнение транскрипции.
3. После завершения работы Whisper в папке появится текстовый файл с результатами транскрибации. Текст будет разбит по строкам с указанием тайм-кодов. Например, у нас в результате обработки с Whisper в исходном файле получилось 184 слова.
Как улучшить текст транскрибации
Когда мы получаем текст после расшифровки аудио, часто требуется его обработка: сократить объем, удалить лишние слова и улучшить читаемость. Мы протестировали три популярных инструмента обработки текста: NLTK, spaCy и Gensim.
NLTK
NLTK — это простая в использовании библиотека для базовой обработки текста. Она отлично подходит для удаления стоп-слов и токенизации (разделения текста на слова).
Установка:
pip install -U nltkИмпортируйте библиотеку и загрузите список стоп-слов:
import nltkfrom nltk.corpus import stopwordsnltk.download('stopwords')
Вот пример кода для обработки текста:
# Загрузка списка стоп-слов для русского языка # Чтение исходного текста # Токенизация текста # Удаление стоп-слов # Сохранение очищенного текста в файл |
После обработки текст будет очищен от лишних слов, таких как «и», «в», «на», сохраняя основное содержание. В нашем тесте текст сократился со 184 до 139 слов, но его смысл полностью сохранился.
spaCy
spaCy — это библиотека, спроектированная для обработки больших объемов текста с высокой скоростью. Помимо удаления стоп-слов, spaCy предоставляет такие функции, как определение частей речи (POS tagging), разметка именованных сущностей и многое другое.
Для начала установим библиотеку и модель русского языка:
pip install -U spacypython -m spacy download ru_core_news_sm
Вот как можно использовать spaCy для очистки текста:
import spacy # Загрузка модели для русского языка # Чтение исходного текста # Анализ текста и удаление стоп-слов # Сохранение очищенного текста в файл |
После обработки текст сократился до 135 слов. Однако, в отличие от NLTK, один из фрагментов текста был некорректно обработан — предложение начиналось с двух запятых.
Gensim
Gensim — это библиотека для тематического моделирования, которая специализируется на работе с большими объемами текстов. Gensim автоматически предоставляет предустановленный список стоп-слов для большинства языков, упрощая задачу обработки текста.
Установите библиотеку с помощью команды:
pip install -U gensimВ Gensim удаление стоп-слов выполняется всего одной строкой:
from gensim.parsing.preprocessing import remove_stopwords # Чтение текста # Удаление стоп-слов # Сохранение очищенного текста в файл |
Текст сократился до 112 слов. Этот способ оказался самым удобным и результативным. Даже при сильном сжатии текста его смысл сохранился, что делает Gensim отличным инструментом для предварительной обработки текстов.
Сравнительный анализ инструментов

Подведем итоги:
- Если вам нужна гибкость и глубокая настройка обработки текста, выбирайте NLTK.
- Если важна скорость работы и готовые модели, используйте spaCy.
- Для максимально простой обработки и удаления стоп-слов лучше воспользоваться Gensim.
15 января, 2025
 Выбираем видеокарту для ИИ до 24GB: обзор и сравнение NVIDIA L4 и T4
Выбираем видеокарту для ИИ до 24GB: обзор и сравнение NVIDIA L4 и T4Сравниваем видеокарты для работы с нейросетями NVIDIA T4 16GB и её обновление в виде NVIDIA L4 24Gb. Детально про технические характеристики, проверим реальную производительность в задачах машинного обучения и разберемся, какая из них лучше справляется с инференсом больших языковых моделей и другими ML-задачами. Это поможет понять, стоит ли в 2026 году выбирать устаревшую T4 или лучше присмотреться к L4.
03 декабря, 2025 Ноябрьский дайджест: тестируем S3 и развиваем GPU-платформу
Ноябрьский дайджест: тестируем S3 и развиваем GPU-платформуВ ноябре тестируем наше S3 хранилище, открыли предзаказ на новейшие GPU NVIDIA RTX Pro 6000 Blackwell Server Edition 96GB и cнизили стоимость аренды сервера с видеокартой NVIDIA L4 24GB. А также написали новые статьи и сделали ряд апдейтов облачной платформы в ноябре.
02 декабря, 2025 Как использовать GPU сервер на максимум для работы с нейросетями
Как использовать GPU сервер на максимум для работы с нейросетямиВ статье рассказываем, как устранить бутылочное горлышко в работе серверов с GPU и заставить работать видеокарту для ИИ более чем на 90%.
13 ноября, 2025