LLM: выбор фреймворка и работа в облаке

Автор: АлександрОпубликовано: 16 декабря, 2024

Большие языковые модели — это мощный инструмент искусственного интеллекта, который имитирует человеческую речь с помощью алгоритмов машинного обучения. В статье разберемся, как LLM работают, для чего их используют и как начать работу с ними на облачном сервере.
Всё об LLM: что это, для чего нужны, как работают и какие бывают
LLM — Large Language Model — дословно переводится как «большие языковые модели». Это тип искусственного интеллекта (ИИ), который применяет алгоритмы машинного обучения для имитации человеческой речи. LLM обучаются на огромных объемах данных: книгах, статьях, веб-страницах. Так они изучают закономерности языка: как слова и фразы связаны между собой, как строятся предложения, какие последовательности чаще всего используются в тексте. Именно поэтому их язык выглядит естественно и очень похож на человеческий. При этом у нейросети нет личного опыта, мнения, сознания и чувств. Ответы основаны на изученных данных и алгоритмах.
LLM применяют в различных областях, чтобы:
- создавать тексты;
- переводить с одного языка на другой;
- поддерживать беседу с человеком в чат-боте;
- генерировать код;
- решать математические задачи.
Один из примеров использования технологии LLM — ChatGPT. Он анализирует запрос и генерирует наиболее вероятное продолжение текста или отвечает на вопрос. При этом использует информацию, полученную на этапе обучения.

LLM классифицируют по доступности моделей на открытые и закрытые, а по типу развертывания — на локальные, облачные и гибридные. Расскажем подробнее об их особенностях и отличиях.
Закрытые, или проприетарные, LLM. Доступ к этим моделям ограничен и требует платной подписки или использования через API. Разработчики таких моделей не раскрывают полную информацию о том, как именно модель была обучена, на каких данных и с каким набором параметров.
Примеры закрытых моделей:
- GPT-4 от OpenAI;
- Claude 3 от Anthropic;
- PaLM (Pathways Language Model) от Google.
Открытые, или опенсорсные, LLM. Эти модели доступны для широкой аудитории. Именно поэтому их используют, модифицируют и обучают любые разработчики, не только создатели. С ними можно свободно экспериментировать.
Примеры открытых моделей:
- GPT-2 от OpenAI;
- T5 (Text-to-Text Transfer Transformer), Gemini Pro 1.5 и BERT от Google;
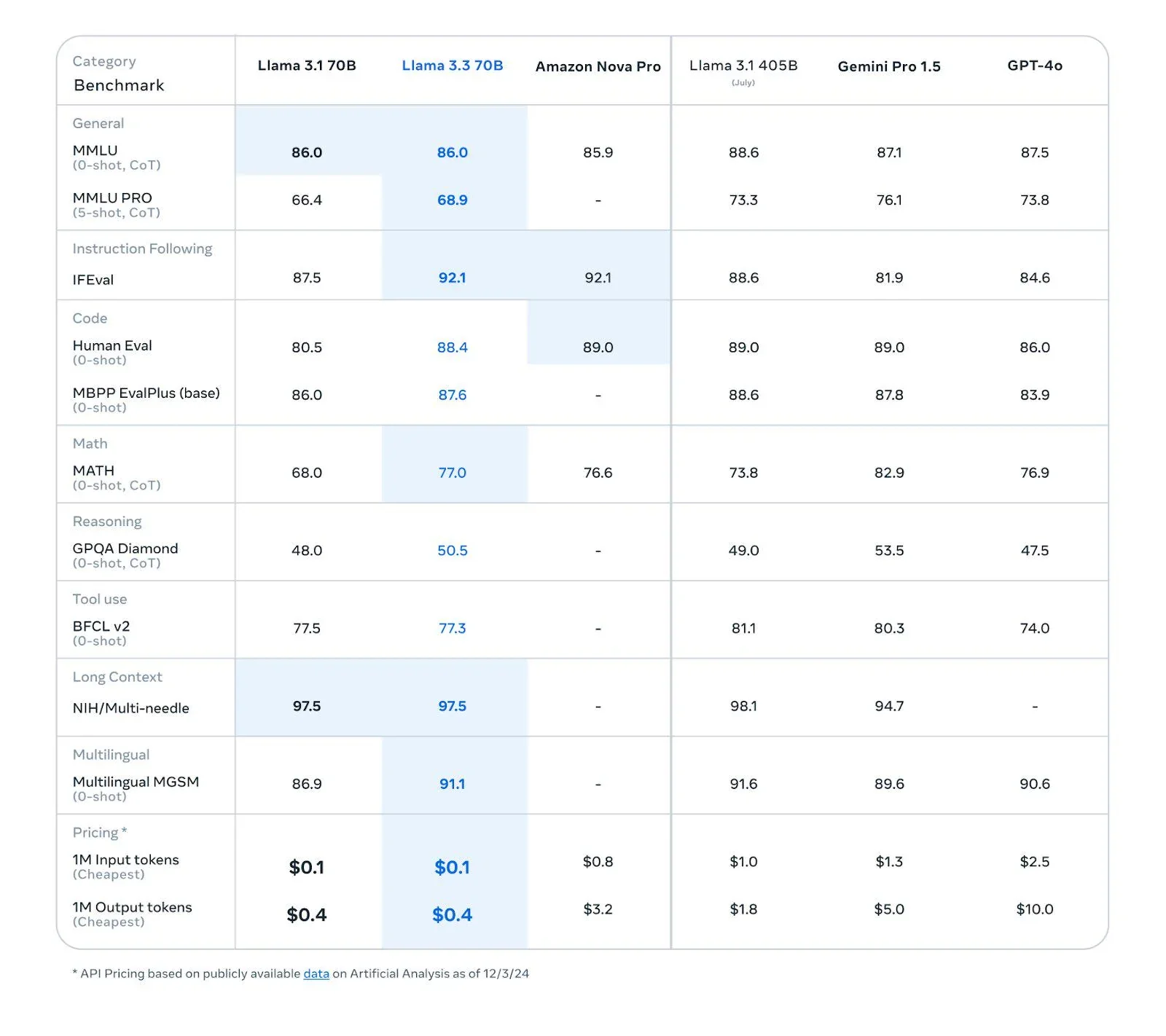
- Llama 3.3.
Локальные LLM. Эти модели работают на устройстве пользователя или на локальных серверах. Они выполняют операции даже без подключения к интернету.
Облачные LLM. Модели размещены на серверах в облаке, пользователи получают к ним доступ через интернет, обычно через API.
Гибридные LLM. Такие модели могут работать как в облаке, так и на локальных устройствах в зависимости от требований задачи.
5 инструментов для управления языковыми моделями
Чтобы интегрировать LLM в систему компании и работать с данными, используют фреймворки и библиотеки. Эти инструменты помогают бизнесу решить разнообразные задачи, например:
- Создавать чат-боты, которые могут интегрироваться с внутренними базами данных и дают точные и контекстные ответы. Чат-бот учитывает предыдущие сообщения от клиента и предлагает решение на основе всей истории запросов.
- Упростить поиск для сотрудников. Система может понимать контекст запросов и предоставлять более точные результаты, поэтому персонал компании будет легче и быстрее находить нужную информацию в корпоративных документах.
- Персонализировать рекомендации. С фреймворками и библиотеками можно создать систему, которая анализирует поведение, запросы и предпочтения пользователя, а затем предлагает подходящие товары или услуги. Точные рекомендации улучшают пользовательский опыт.
- Быстро анализировать юридические документы и договоры и снижать риск ошибок. Системы на базе LLM автоматически извлекают ключевые данные из контрактов, например суммы, сроки, условия, и проверяют, соответствуют ли они стандартам.
- Анализировать большие объемы данных и создавать отчеты на их основе.
Рассмотрим несколько популярных инструментов: фреймворки LlamaIndex, LangChain, Hugging Face agents, Haystack и библиотеку vLLM.
Фреймворк LlamaIndex — это мощный инструмент для обработки естественного языка, который использует не только данные из интернета, но и собственные источники: документы, базы данных и API. Он может загружать, структурировать и запрашивать данные и легко интегрируется с популярными языковыми моделями, такими как ChatGPT и Bard. Llama быстро и качественно выдает результат при небольших затратах, включает многоязычные текстовые модели и модели «текст — изображение».
Ключевые особенности LlamaIndex:
- Поддержка разных типов данных. Может получать информацию более чем из 160 источников и форматов, включая API, PDF, SQL.
- Эффективное хранение и извлечение информации. Интегрируется с 40 и более хранилищами векторов и базами данными. Пользователи быстро находят нужную информацию.
- Сложные рабочие процессы LLM. Позволяет создавать системы с дополнительным извлечением (RAG).
- Оценка качества извлечения и производительности ответов LLM.
- Открытый доступ для разработчиков. Исследователи могут настраивать и использовать фреймворк под себя благодаря открытому исходному коду. Так образуется сообщество, которое развивает LlamaIndex.
С помощью LangChain разработчики строят сложные чат-боты, которые могут обрабатывать запросы пользователей и адаптироваться к контексту общения. Фреймворк помогает бизнесу автоматизировать процессы, улучшить взаимодействие с клиентами и повысить эффективность работы с данными.
Ключевые особенности LangChain:
- Простота использования. Фреймворк подходит даже для начинающих разработчиков, поэтому интерфейс интуитивно понятный, в нем легко разобраться.
- Ветвящиеся диалоги. LangChain поддерживает создание многоступенчатых и ветвящихся диалогов, поэтому модели ведут более естественные и осмысленные беседы с пользователями.
- Интеграция с внешними API. Фреймворк позволяет легко интегрировать различные API, что расширяет возможности взаимодействия чат-ботов с внешними системами.
- Персонализация ответов. LangChain генерирует разные ответы в зависимости от действий пользователя. Так повышается качество коммуникации.
- Поддержка различных языков. LangChain поддерживает работу с текстом на нескольких языках, поэтому подходит для международных проектов.
Фреймворк Hugging Face предлагает мощный и гибкий инструментарий для разработки пользовательских агентов. Можно легко создавать системы, которые выполняют сложные задачи, используя возможности LLM.
Ключевые особенности Hugging Face:
- Интерактивные диалоги. Hugging Face ведет диалоги с пользователями, сохраняя историю взаимодействия. Именно поэтому его общение более естественное и последовательное.
- Интеграция внешних API. Благодаря этому фреймворк может выполнять более сложные задачи — например, получить доступ к данным в реальном времени или выполнять операции с использованием сторонних сервисов.
- Модульная архитектура. Hugging Face обладает модульной архитектурой, что позволяет легко добавлять новые функции и инструменты. Например, разработчики могут использовать встроенные инструменты для выполнения конкретных задач, таких как генерация изображений или перевод текста.
- Простота использования. Фреймворк предлагает удобный API для быстрого создания и развертывания агентов. Разработчики могут легко настраивать агентов под свои нужды, используя простые команды.
Мощный фреймворк с открытым исходным кодом предназначен для создания приложений на основе больших языковых моделей и генеративных конвейеров, дополненных поиском (RAG). Он объединяет поисковые и генеративные методы, поэтому создает более точные и релевантные результаты. Haystack помогает бизнесу решать задачи обработки больших данных, улучшать взаимодействие с клиентами и повышать эффективность рабочих процессов. Разработчики могут легко адаптировать фреймворк под свои сценарии использования и создавать приложения на основе LLM.
Ключевые особенности Haystack:
- Широкие возможности настройки. Можно использовать фреймворк Haystack, а также строить на его основе собственные решения: простые приложения RAG и сложные системы с множеством взаимодействий.
- Многофункциональность. С Haystack создают приложения, которые будут обрабатывать не только текст, но и изображения и аудио.
- Гибкость в создании конвейеров. Разработчики могут создавать сложные конвейеры с ветвлением и циклами для поддержки многофункциональных рабочих процессов агентов.
- Интеграция с генеративным ИИ. Фреймворк легко интегрируется с популярными моделями, такими как GPT-3 и BART.
Это быстрая и удобная библиотека для инференса и обслуживания больших языковых моделей. Она моментально генерирует текст благодаря современным методам обработки запросов, эффективному управлению памятью и поддержке непрерывной пакетной обработки запросов. Фреймворк vLLM также обеспечивает быструю работу модели с помощью CUDA/HIP-графов. Библиотека совместима с API OpenAI и работает на различном оборудовании, например NVIDIA и AMD GPU, Intel CPU и GPU.
Ключевые особенности vLLM:
- Алгоритм внимания. Это ускоряет процесс обработки данных и позволяет эффективно управлять большим количеством запросов.
- Быстрая генерация текстов. vLLM подходит для приложений, требующих высокой пропускной способности.
- Поддержка различных алгоритмов декодирования. Например, параллельную выборку и лучевой поиск. Это оптимизирует процесс генерации текста в зависимости от конкретных требований.
- Простой и удобный API, совместимый с OpenAI. Чтобы интегрировать vLLM в приложение, разработчикам достаточно указать URL конечной точки и не тратить время на настройку нового интерфейса.
Минимальные требования к оборудованию в облаке
Для обучения и инференса LLM нужен мощный сервер с высокопроизводительными процессорами и видеокартами. Облачные решения предоставляют доступ к таким ресурсам без необходимости покупать и поддерживать дорогостоящее оборудование.
Процессоры CPU. Для обработки и обучения моделей на облачных платформах необходимы процессоры с высокой производительностью. Топовые модели процессоров от Intel и AMD, такие как Intel Xeon и AMD EPYC, с частотой от 3,8 ГГц. Они обеспечивают высокую производительность системы.
Видеокарта GPU. Графические процессоры позволяют параллельно обрабатывать огромные объемы данных. Для базового применения в работе с ИИ достаточно видеокарт с 24 Гб видеопамяти, например NVIDIA L4. Чтобы обрабатывать большие объемы данных или обучать крупные LLM, нужны высокопроизводительные видеокарты, например NVIDIA L40S с памятью 48 Гб GDDR6. Для эффективной работы с самыми большими моделями ИИ подойдет NVIDIA H100 на 128 Гб.
Оперативная память RAM. При использовании GPU оперативная память помогает переносить данные модели из хранилища в видеопамять, поэтому ее объем должен быть как минимум равен объему видеопамяти, а лучше превышать ее в полтора-два раза. Даже если модель загружена в видеопамять, RAM требуется для системных нужд, таких как файл подкачки.
Гибридный подход, который сочетает использование CPU и GPU, позволяет эффективно работать с моделями, которые не помещаются в VRAM. Для быстрого инференса важно иметь SSD с высоким уровнем производительности и достаточно свободного места, так как некоторые модели могут занимать сотни гигабайт данных.
Операционная система. Для работы с LLM лучше всего подходит Linux — операционная система поддерживает NVIDIA Collective Communications. Модель может работать и на Windows, но ее техническая документация будет хуже.
Пошаговая инструкция по установке и настройке языковой модели
Облако mClouds соответствует всем требованиям для работы с LLM:
- Процессоры — Intel Xeon Gold 6354 до 3,9 ГГц или EPYC 9374F 3,85–4,1 ГГц.
- Видеокарта — NVIDIA L4 или L40S в зависимости от выбранной платформы.
- Операционная система — Windows Server или Linux.
В пошаговых руководствах подробно и со скриншотами описано первое подключение облака mClouds к серверу Windows Server и к серверу Linux.
Чтобы установить и настроить саму языковую модель, последовательно выполните следующие действия:
1. Установите библиотеки для работы с LLM.
Например, vLLM, о которой рассказывали в статье, или другие популярные. Они нужны для обработки человеческого языка. Импортируйте их и настройте окружение.
2. Загрузите базовую модель.
Выберите подходящую предварительно обученную модель и укажите настройки.
3. Добавьте метод настройки моделей LoRA.
Определите функцию для подсчета обучаемых параметров, активируйте контрольные точки градиента и подготовьте модель для обучения. Так метод LoRA позволяет экономить память при обучении.
4. Проверьте работу модели с помощью тестового вопроса.
Подготовьте запрос для модели, настройте параметры генерации текста, токенизируйте запрос и сгенерируйте текст без расчета градиента. LLM должна предоставить читаемый текстовый ответ.
5. Загрузите набор данных.
Можно использовать формат CSV. Создайте функции для генерации и токенизации запросов и подготовьте данные для обучения.
6. Настройте параметры и начните процесс обучения модели.
Создайте объект для настройки обучения, отключите кеширование модели и начните обучение.
7. Сохраните модель и запустите инференс.
Сохраните модель после обучения и загрузите ее для инференса. Подготовьте запрос для инференса и сгенерируйте текст.
Вы можете протестировать работу LLM в облаке mClouds: оставьте заявку, и мы развернем для вас GPU-сервер — он будет доступен сразу.
16 декабря, 2024
 Выбираем видеокарту для ИИ до 24GB: обзор и сравнение NVIDIA L4 и T4
Выбираем видеокарту для ИИ до 24GB: обзор и сравнение NVIDIA L4 и T4Сравниваем видеокарты для работы с нейросетями NVIDIA T4 16GB и её обновление в виде NVIDIA L4 24Gb. Детально про технические характеристики, проверим реальную производительность в задачах машинного обучения и разберемся, какая из них лучше справляется с инференсом больших языковых моделей и другими ML-задачами. Это поможет понять, стоит ли в 2026 году выбирать устаревшую T4 или лучше присмотреться к L4.
03 декабря, 2025 Ноябрьский дайджест: тестируем S3 и развиваем GPU-платформу
Ноябрьский дайджест: тестируем S3 и развиваем GPU-платформуВ ноябре тестируем наше S3 хранилище, открыли предзаказ на новейшие GPU NVIDIA RTX Pro 6000 Blackwell Server Edition 96GB и cнизили стоимость аренды сервера с видеокартой NVIDIA L4 24GB. А также написали новые статьи и сделали ряд апдейтов облачной платформы в ноябре.
02 декабря, 2025 Как использовать GPU сервер на максимум для работы с нейросетями
Как использовать GPU сервер на максимум для работы с нейросетямиВ статье рассказываем, как устранить бутылочное горлышко в работе серверов с GPU и заставить работать видеокарту для ИИ более чем на 90%.
13 ноября, 2025