Cisco CSR 1000v: Надёжность – залог успеха. Часть 2

В нашей предыдущей статье о маршрутизаторе в виртуальном исполнении CSR 1000v от Cisco Systems мы постарались в максимально простой и краткой форме описать основные возможности этого замечательного продукта. Идеология подобных решений (и этого, в частности), на самом деле, очень проста и эффективна, т.к. виртуальное исполнение позволяет задействовать и максимально утилизировать имеющиеся вычислительные мощности. А, если учесть, что целевая область применения CSR – облачная инфраструктура, то ресурсов для его работы должно быть достаточно. При этом, повышается гибкость применения такого «устройства», т.к. его можно использовать на границах виртуальных сетей. Однако, в этой статье хотелось бы поговорить о том, как максимально повысить надёжность сети, минимизировать или даже свести к нулю время возможного простоя и не допустить появления единой точки отказа даже для небольшой группы виртуальных машин.
Средства обеспечения отказоустойчивости в нашем конкретном случае можно разделить на следующие три небольшие группы:
1. Механизмы обеспечения отказоустойчивости гипервизора.
2. Протоколы отказоустойчивости шлюза по умолчанию (FHRP – First Hop Redundancy Protocol).
3. Механизмы кластеризации, имеющиеся в ОС маршрутизатора.
О первой группе было кратко сказано в предыдущей статье. В нашем случае, при работе с виртуализацией VMware, есть 2 варианта: High Availability (HA) и Fault Tolerance (FT). Отличаются они друг от друга разными последствиями при выходе из строя хоста, на котором работала активная виртуальная машина (далее ВМ). В случае с HA ВМ перезапустится на другом хосте, при работе функционала FT – переходит в активное состояние теневая копия ВМ, работающая параллельно на другом хосте. Соответственно, для HA возможный простой составит от 5 минут в зависимости от других факторов (запустилась ли ВМ на другом хосте, хватило ли вычислительных ресурсов, была ли сохранена конфигурация CSR, имеются ли резервные копии). Если говорить о VMware FT, то здесь простой будет незаметен. Однако, FT во многих сценариях не применим, т.к. требует аппаратной совместимости серверов, где работают копии ВМ, в части наборов инструкций процессоров, а также, имеет ограничения в плане пропускной способности и увеличивает задержку сети. Ниже приведен ряд примеров того, как влияет использование FT при различных условиях.
На рисунке ниже показано, как влияет FT на пропускную способность виртуальной машины (ВМ) для сети со скоростью 1 Гбит/с.

На следующем рисунке аналогичный показатель, только, для 10 Гбит/с.
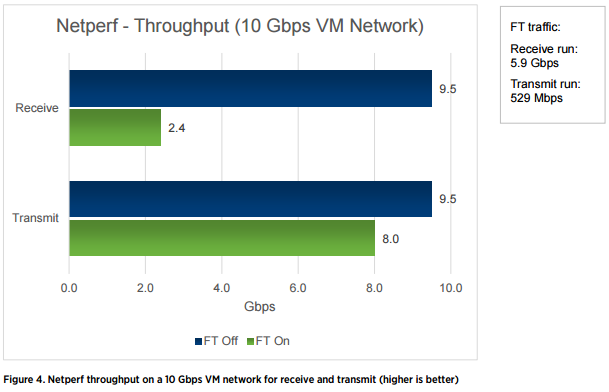
А вот так уже увеличивается задержка при включении FT для виртуальной машины.
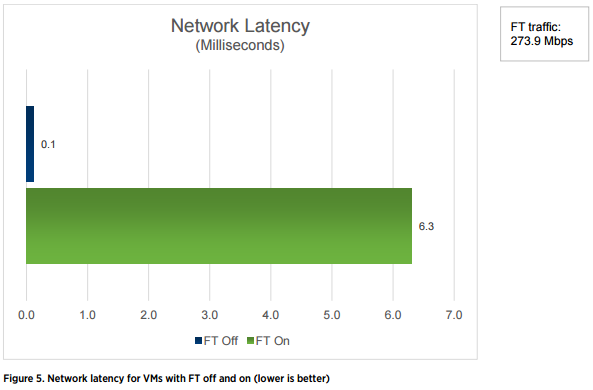
Отсюда можно сделать вывод, что FT может быть использован не для всех сервисов, а только для тех, которые не требовательны к характеристикам сети (пропускная способность, задержка, джиттер и т.п.). Для CSR 1000v, как для сетевого устройства, любое негативное влияние на сетевые показатели нежелательно.
Переходим ко второй группе средств обеспечения отказоустойчивости. Далее у нас по плану семейство протоколов отказоустойчивости шлюза по умолчанию (FHRP – First Hop Redundancy Protocol). Как мы знаем, в контексте оборудования Cisco, основных представителей этой группы всего три: VRRP, HSRP и GLBP. Стоит сразу отметить, что данная группа протоколов обеспечивает лишь отказоустойчивый и относительно непрерывный «user experience», то есть обеспечивает резервирование и активное переключение нагрузки (либо балансировку), но не имеет ряда преимуществ других решений, как, например, единая точка управления в случае с методами из группы 1.
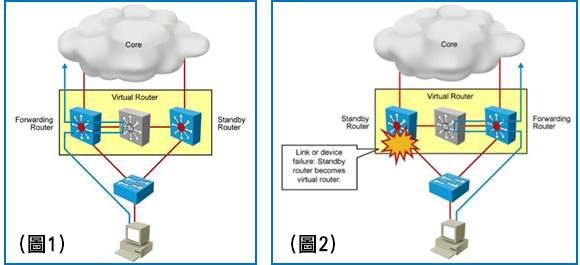
Подробно останавливаться на данной группе решений не будем, т.к. информация об указанных протоколах в избыточном объёме содержится в официальной документации Cisco. Скажу лишь кратко, что VRRP и HSRP подразумевают наличие одного активного «устройства» (не обязательно физического, т.к. для каждого интерфейса можно настроить отдельную группу), которое осуществляет передачу данных и одного или нескольких в режиме ожидания. GLBP отличается тем, что подразумевает балансировку между интерфейсами, входящими в одну группу.
Стоит отметить, что для корректной работы протоколов FHRP в виртуальной среде, то есть при использовании CSR 1000v, необходимо установить параметры «MAC address changes», «Forged transmissions» и «Promiscuous mode» в настройках безопасности для портовой группы виртуального коммутатора в значение «Accept». Это требуется, потому что при работе данных протоколов идёт работа с виртуальным MAC-адресом, что фактически приводит использованию нескольких MAC-адресов виртуальной машиной, а это по умолчанию не разрешается.
Также, скажу пару слов о производительности. Использование протоколов семейства FHRP значительно не влияет на сетевые показатели и загрузку ЦП маршрутизатора. Пропускная способность при этом также не пострадает.
Итак, наконец, переходим к последней группе – «кластеризация». Под этим словом в рамках данной статьи будем понимать механизм обеспечения отказоустойчивости, реализованный в IOS XE под названием High Availability, а если быть точным, то Firewall Box to Box High Availability.
Поддержка данного механизма появилась в ПО Cisco IOS XE Release 3.14S. Преимуществом данной технологии являются быстрая сходимость (обнаружение сбоя) и синхронизация состояний NAT и Firewall. Подробную информацию о настройках лучше подсмотреть в документации Cisco здесь. Для работы данного функционала требуется технологический пакет лицензий уровня Security или AX и не забываем про настройки безопасности портовой группы виртуального коммутатора аналогично FHRP.
Архитектура решения выглядит следующим образом:
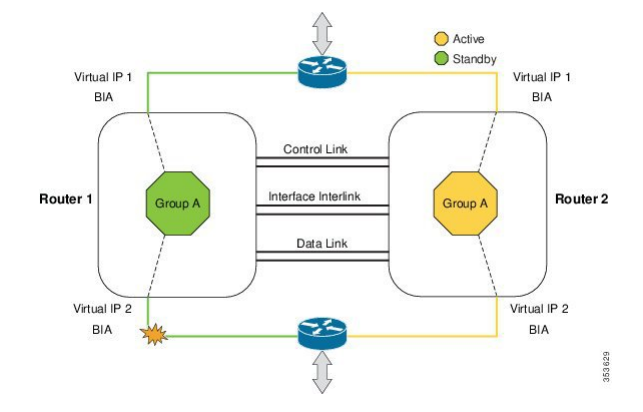
Собственно, на этом закончим краткий обзор инструментов повышения отказоустойчивости относительно применения для Cisco CSR 1000v в виртуальной среде на базе VMware. Для кого-то информация окажется не новой, а кто-то, я надеюсь, найдёт в ней что-нибудь новое и полезное для себя. Не судите строго и используйте подходящие инструменты для защиты ваших сервисов. Спасибо!
 Первый теплый дайджест: обновили GPU-платформу, тарифы и поддержку
Первый теплый дайджест: обновили GPU-платформу, тарифы и поддержку
В мае у нас было много обновлений, а именно - открыли для заказа диски PCIe Gen 5 уже с видеокартами NVIDIA L4 24 ГБ, добавили Ubuntu 26.04 в доступные образы для IaaS, обновили сайт и улучшили раздел поддержки. Сделали обзор нашей GPU платформы.
05 июня, 2026 Запустили новую облачную GPU-платформу и другие обновления марта
Запустили новую облачную GPU-платформу и другие обновления марта
Добавили новый кластер с новейшими процессорами AMD EPYC 9555 с 128 физическими ядрами на узел и рабочей частотой 4,2 ГГц. Еще больше скорости для ваших задач с 1С , нейросетями, работе с VDI и других задач, требующих высокой производительности. А еще добавили пул видеокарт NVIDIA L4 24GB и NVIDIA A16 64GB. Вошли в рейтинг облачных провайдеров резервного копирования и писали интересный контент!
02 апреля, 2026 Февральский дайджест обновлений - больше GPU в облаке, новые процессоры и партнерская программа
Февральский дайджест обновлений - больше GPU в облаке, новые процессоры и партнерская программа
В январе и феврале мы увеличили количество доступных видеокарт NVIDIA L4 и NVIDIA A16, вводим в продуктив кластер на новых серверах Dell R7725 с 64-х ядерными процессорами AMD EPYC 9555 с постоянной частотой в 4.2 ГГЦ. А еще заняли место в топе рейтинга партнерских программ облачных провайдеров и писали интересное на Хабр!
07 марта, 2026